- Azonnali VGA-s kérdések órája
- Havi kétszáz leégett tápcsatlakozó fut át egy Los Angeles-i szervizen
- Analóg kapcsolós klaviatúrák triója a Razer fémjelzésével
- TCL LCD és LED TV-k
- Azonnali notebookos kérdések órája
- Fejhallgató erősítő és DAC topik
- Kompakt vízhűtés
- Milyen asztalt vegyek?
- Nem indul és mi a baja a gépemnek topik
- Melyik tápegységet vegyem?
Hirdetés
-


Közel 1 billió dollárt vesztettek a big tech óriásai
it Nagyot kaszáltak a shortolók, az úgynevezett Magnificent 7 közel 1 billió dollárt veszített a piaci értékéből a múlt héten.
-


Engedélygyűjtésbe kezdett a Poco táblagépe
ma 33 wattos töltéssel és 8 megapixeles kamerákkal várható a Poco Pad.
-


Toyota Corolla Touring Sport 2.0 teszt és az autóipar
lo Némi autóipari kitekintés után egy középkategóriás autót mutatok be, ami az észszerűség műhelyében készül.






-

PROHARDVER!
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-
#5052
 lezso6
HÁZIGAZDA
VaniliásRönk
#5049
lezso6
HÁZIGAZDA
VaniliásRönk
#5049
válasz
 VaniliásRönk
#5049
üzenetére
VaniliásRönk
#5049
üzenetére
Legalább UP-olták a topicot.
![;]](//cdn.rios.hu/dl/s/v1.gif)
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
"A Deneb tuti nem 8MB L3-as"
Csak simán cache-t írtak, tehát ebben benne van az L2 is pl. 4*512kB + 6MB = 8MB.
 Tessék figyelni.
Tessék figyelni.  Az Agenánál is 4MB-ot írtak.
Az Agenánál is 4MB-ot írtak.De attól még megint 2 hiba lesz benne, mert találtam én is egyet: A "Propos" (vagyis Propus) alatt 4 Core-t írnak 4 cores helyett.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 #95904256
#8883
üzenetére
#95904256
#8883
üzenetére
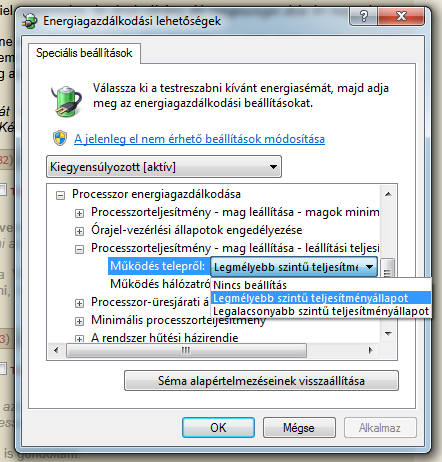
Így kell aktiválni. A szandimnál bepróbálkoztam vele, de nagyon nincs érezhető hatása, sőt, mintha többet is fogyasztana ezzel. Gondolom azért, mert nem tudja külön vezérleni / lekapcsolni a magokat. Na de majd a bull.

A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
-
A dupla etetésnek köszönhetően ez elvárható lenne.
 De akkor ehhez mérten az eddigi modulon belüli skálázódásnak kakinak kéne lennie, legalábbis a 90%-ból nem tudom hogy lehet 140%-ot csinálni.
De akkor ehhez mérten az eddigi modulon belüli skálázódásnak kakinak kéne lennie, legalábbis a 90%-ból nem tudom hogy lehet 140%-ot csinálni. [ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Az volt az alap, hogy egy szálon 10%-ot gyorsul, több szálon (sysoft sandra) meg 30%-t. Ebből következtettem arra a (hülyeségre), hogy tehát ha ezelőtt egy modulnál szállal 100% a skálázódás és két szállal 190%, és az új ez még jobban skálázódik a hatékonyabb etetés miatt, akkor 240%-ot kapunk két szálra.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
-
-
válasz
 eastone1
#13951
üzenetére
eastone1
#13951
üzenetére
Mivel még hivatalosan ki sem jött, szerinted hogy lehet tudni, hogy kihajcsaje?
Majd ha lesznek a tesztek kiderül. Egyébként is, csak 10-15%-kal gyorsabb CPU-ban, szóval majd a mantle fogja eldönteni, hogy mennyire hajcsa ki, arra meg még várni kell.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Lenne egy kérdésem, ha már ennyire benne vagytok a témában, bár lehet kicsit nagyon előrefutok illetve orbitális baromság.
Tegyük fel hogy elfogy a nanométer, azonos területen kell majd sokkal jobbat kihozni a jelenlegi CPU ISA-kból. Viszont előbb-utóbb ezek a lehetőségek is elfogynak mindenhol, és mindenképp új ISA-kat kell kifejleszteni a nagyobb teljesítményhez, de a kompatibilitást valahogy meg kell oldani. Itt jön képbe a vISA, így nincs szükség natív kódra, azaz az ISA folyamatosan változhat az egyre jobb teljesítményért. Ha jól értelmezem, kicsit a jelenlegi Java / .NET-féle VM megoldásokhoz hasonlít ez, csak jóval mélyebben. Utóbbiak már bizonyítottak, így lehet lassan eljön a vISA-k kora, akár CPU-n is?
Ha egy kicsit még mélyebbre ások, akkor azt látom, hogy a x86 CPU-k belül gyakorlatilag RISC-ek (utasítás-szám szempontból, nem load / store), szóval ez valamilyen szinten belül már rég megtörtént. Pl ott az ősrégi AMD K5 architektúra, aminek a belsejében egy 29k RISC processzor van, de kívülről x86.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Na pont erre gondoltam, hogy ha a gyártástechnológia fejlesztése egyre kevésbé éri meg, akkor a microarchitektúra megtervezésére kell jobban odafigyelni. Viszont mikor már ez utóbbinak fejlesztése is korlátokba ütközik a teljesítménynél (lásd haswell, ahol minimális volt a növekedés), új architektúrára van szükség. Ez utóbbinál viszont korlátozó az eltérő ISA, így az Intel az AVX kiterjesztéssel próbálkozik (ahogy eddig is ment az MMX, SSE), ami úgymond egy köztes út, megtartva a kompatibilitást, míg az AMD radikálisabb megoldásban keresi a jövőt, és GPU-val házasítja a "fix" CPU-t.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Ja, én is inkább az egész gyártástechnológiára gondoltam, mint a nanométerre. Erről lehetne egy részletesebb tudástárcikk, esetleg akár vélemény cikk a nagyobb terjedelem miatt, mert sokaknak (nekem is) elég homályos, s szerintem nem csak én vagyok rá kíváncsi, hogy most mi van. Jelenleg csak azt tudom, hogy egyes gyártók nanométereit nem lehet összehasonlítani, nemcsak azért, mert azok gyakorlatilag "nem is annyik amennyik", hanem mert az általad is említett "thin library" is rengeteget közrejátszik. Gondolom ez utóbbi a cpu-kban használt egységek építőköveinek halmaza.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
AMD-nek szerintem ez szerverben az igazi szopás. Legalábbis az én szemszögemből haszontalan egy APU egy általános web vagy adatbázis-szerverbe. Elviekben tök jó lenne mindkettőre, főleg web, mert ott tényleg rengeteg szál fut (minden letöltéshez egy) aszinkron egyszerre. Adatbázis terén szintén jó lenne, bár itt nagyon fontos lenne a párhuzamosan több aszinkron kérés a webről (már ha nem kell egy tranzakcióban lenniük), amivel messze jobb kihasználtságot el lehetne vele érni az adatbázis-szerveren, mert jelenleg a legtöbb helyen egyszerre csak egy szinkron kérést küld a web az adatbázisnak, ami a válaszidőt hazavágja.
Közbe egy gyors gúglizással találtam egy érdekességet: PGStrom
Itt egyértelműen látható, hogy egy közös címterű APU lenne az igazi, a dGPU-t nagyon korlátozza a PCIE.
De ha ezek elterjednének, portolnának mindent APU-ra, akkor már rég nem sírnék. Egy dGPU szvsz már azért bukó, mert relatív nagyon kevés memóriája van, ami nem is bővíthető.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Szerintem csak így tudnak csak haladni, hogy piacra dobják, s élesben tesztelnek. Ha háttérben csinálnák, sokkal többe kerülne, hisz vinni kéne a hagyományos CPU vonalat is. Intelnél ez megy, mivel van pénz, az AMD-nek viszont muszáj egy lapra feltenni mindent (APU). Ez utóbbi eddig a konzoloknál szerencsére bejött, így a fejlesztők már ráálltak, reméljük a legjobbakat.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Ez így van, de én arra gondoltam, hogy eddig csak úgy lógott a levegőben APU, nem igazán használta semmi, viszont a konzolokkal most ráállt nem kevés fejlesztő az APU rejtelmeinek kiismerésére. S itt majd a rengeteg összegyűlt tapasztalat fog számítani, mely később a PC-k területén is hasznosítható lesz.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Miért ne lehetne hasznosítani? Általános ismeretekről beszélek, nem arról, hogy hogyan kell konkrét XY algoritmust APU-ra megírni. Pl ha egyszer megtanultam OOP-ban programozni valamilyen nyelven, akkor máshol is fogok tudni, persze nem rögtön ugyanazon a szinten, de sokkal könnyebb lesz, mert a gondolkodásmód már megvan. Az OOP-t egyébként lehet cserélni kb bármire.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
De itt arról volt szó, hogy bármilyen SSE2+ x86-os CPU-n fut, s ki lesz használva az AVX, már ha tud ilyet. Ez nem az AMD mellett szólt, hanem úgy általában, mindenre vonatkozóan. Az meg, hogy majd lesz-e a Kaveri / Carrizo iGPU-hoz is komolyabb támogatás, az később kiderül. Azt meg nem tudom honnan vetted, hogy a HSA az AVX-re lesz a legjobb. Egyelőre most semmire sem jó. De majd lehet bármire jó lesz.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 Thrawn
#15511
üzenetére
Thrawn
#15511
üzenetére
Pedig az 8 mag, ha jól tudom funkcionálisan kb az AVX utasításból tud csak egy modul egyszerre csak egyet végrehajtani, mert az FPU 256 bit széles (keskenyebb utasításoknál "kettévágódik"). De minden másból tud a modul egyszerre kettőt végrehajtani.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
Thrawn
#15584
üzenetére
Szerver területén nem az FB-DIMM a problémájára adna választ a HBM iránya? Azaz túl sok lenne a vezetékezés a sok ram slot miatt, s ezt trükközik ki az FB-DIMM segítségével. A HBM-nek hasonló a lényege, hogy a sok vezetéket megoldja az interposer kis területen. Csak itt a nagy sebesség helyett a nagy méretű memória cél. Bár ezt gyártani akkor is szívás, s az elején max kisebb 64GB körüli memóriás chipeket tudnék elképzelni, kisebb szerverekbe.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 Valdez
#15660
üzenetére
Valdez
#15660
üzenetére
Anno az AMD igencsak versenyképes terméket hozott, a K7-ek celeron árban hozták a P4-ek szintjét, a K8-ak meg ugyanolyan teljesítmény mellett megalázták a kazán P4-eket fogyasztásban. Aztán jött a Core 2 Duo, s azóta az AMD csak szenved.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
#15663
lezso6
HÁZIGAZDA
Petykemano
#15662
válasz
 Petykemano
#15662
üzenetére
Petykemano
#15662
üzenetére
Az is közrejátszik, hogy volt az Intelnek nem egy gusztustalan húzása, amiért megbüntették őket. De a K8-at tényleg nagyon sokáig húzták, elkényelmesedtek.
A C2D ellen a K10 jött, csak hát ez utóbbit nem 65 nanométeren kellett volna kihozni. Mire eljutottak 45 nanométerre, már kint volt az első Core i generáció, így az is bukó volt. Majd jött a Bulldozer a Sandy ellen, de hiába, máig nincsenek annyira elterjedve a 8 szálat kihasználó alkalmazások, melyek már akkor kellettek volna, hogy labdába rúghasson a Bull. Így az AMD nekiállt APU-zni, amiből lett ugyan 2 konzol, de PC-nél ez senkit sem érdekel.
A Radeonok nem hasonlíthatóak Bulldozerhez, mivel GCN simán versenyképes, nem tudott az NV elhúzni teljesítményben, ahogy az Intel tette a CPU-knál. Persze a fogyasztás / teljesítmény aránya jobb, de itt sincs olyan durva különbség (+20-30%), mint proci fronton (+60-100%), vagy ahogy hangoztatják. A Radeonok problémája hogy relatíve kevés fogy, marketing kéne alájuk, ebben eléggé béna az AMD. Hiába okosabb a GPU-juk, ha a konkurencia sokkalta nagyobb részesedése miatt nem lehet kihasználni. Bár ez most változni fog a Pascallal. Egyébként az aszinkron compute csak a jéghegy csúcsa.

A Fermit nem nevezném bukásnak, hisz az 5xx-szel végül sikereres megcsinálták amit kellett. Ez az ami az AMD-nek a K10-zel nem sikerült. A többi az oké.
A 20 nanométer hiánya legjobban szerintem az AMD-nek tett be, mert pl azzal talán jobb CPU-i lennének most, s a GCN-ek fogyasztása is alacsonyabb lenne. GPU fronton az NV a Maxwell forgatókönyvével nem is intézhette volna el a jobb fogyasztás kérdését 28nm-en, de ennek ára is volt. Én nagyon várom már ezt a 14nm-t, mert új lehetőségek nyílnak, lásd Zen meg Pascal (illetve GCN "2.0"), remélem mindegyik jól sikerül, s lesz értelmes verseny.
szerk: ohh, basszus, most nézem melyik topikban vagyok, akkor rövidebbre fogtam volna az offolást.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 Yutani
#15682
üzenetére
Yutani
#15682
üzenetére
Azért tűnt el, mert próbál intelligens lenni. Olyan cikket ajánl, amit még nem láttál, de egy cikket max 7 alkalommal ajánl, utána érdektelennek veszi. Az, hogy konkrétan mit ajánl az meg elég bonyolult.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 apatyas
#16006
üzenetére
apatyas
#16006
üzenetére
Ja, hogy úgy. De hogy lehet így számolni?
 Ez alapján ha a HT +0%-ot hoz, akkor is 50% a "skálázódás" mértéke, ezzel a elcseszett módszerrel a 0%-os HT "skálázódás" csak úgy érhető el, ha lefagy a rendszer.
Ez alapján ha a HT +0%-ot hoz, akkor is 50% a "skálázódás" mértéke, ezzel a elcseszett módszerrel a 0%-os HT "skálázódás" csak úgy érhető el, ha lefagy a rendszer.  Én meg már néztem, hogy akkor az OS-ok ütemezőjét kéne frissíteni a bullhoz hasonlóan, hogy jó legyen a HT-s teljesítmény, azaz minden szál lehetőleg külön magon menjen.
Én meg már néztem, hogy akkor az OS-ok ütemezőjét kéne frissíteni a bullhoz hasonlóan, hogy jó legyen a HT-s teljesítmény, azaz minden szál lehetőleg külön magon menjen.szerk: a HT meg a CMT közötti különbség amúgy tiszta. Egyébként nekem is tök az maradt meg, hogy a HT +60% körülit dob, nem tudom miért, gondolom valami vérpista szájából.

(#16008) Oliverda: Ja, hát baromság is lett volna az intel részéről, ha a P4 óta, csak most jöttek volna rá, hogy az OS ütemezőt is okosítani kéne a HT megfelelő kihasználásához.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
-
válasz
 t72killer
#16421
üzenetére
t72killer
#16421
üzenetére
A SHA nem csak checksumra jó.
Ugye Secure Hash Algorithm, pl PH! motorja is nem egy helyen használja. Desktop példát mondjuk nem tudok mondani az TLS-en kívül, szvsz leginkább szerver-szinten lesz kimutatható haszna a hardveres SHA-nak.[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
t72killer
#16424
üzenetére
Konkrét példa pl a kilépési link itt a PH!-n. Egy hash van az URL-ban, hogy ne tudj vele trollkodni a fórumban azzal, hogy belinkeled, rákkatint a júzer, aztán kiléptetődik. Vagy pl egyes generált mérő URL-öknél is használható, hogy csak egyszer lehessen azokat meghívni. Ha többször is meg lehetne (hacker júzer épp unatkozik), akkor torzulna az eredmény.
S ez csak az a pár dolog, ami engem érint, pl egy git verziókövető rendszernél egy-egy sha azonosítja az egyes verziókat, mert szám inkrementálással nem lehet (párhuzamosan fejleszthetnek többen, több ágon), olyan hash kellett, aminél nagyon pici az ütközés valószínűsége.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
 Goose-T
#16762
üzenetére
Goose-T
#16762
üzenetére
Itt nem a kompatibilitásról van szó, hanem pl az olyasmiről, mint hogy nagyon régen hogy egy újabb gépen túl gyorsan futott egy játék. S akkor ez még egy egyszerű, megoldható probléma (turbo gomb), képzeld el ezt egy mai rendszerrel, ahol több szál dolgozik.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
válasz
Yutani
#16764
üzenetére
Azon én is, csak egy egyszerű példának hoztam fel. Itt inkább olyasmi gondok lehetnek, hogy a kód mikroarchitektúrára optimalizált, akár olyan szinten, hogy figyelembe vették egyes utasítások ciklusidejét. Illetve lehet ami a Jaguaron jól fut, a Zenen nem. Na meg ott az errata, stb.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Ha nincs chipset és csak 24 PCIe sáv lesz a CPU-ba integrálva, az szvsz elég bukó a a HEDT-nek, hisz először oda jön, nem? Bár lehet úgy csinálják, hogy a high-end CPU-k több PCIe sávot kapnak, de ennek a technikai kivitelezhetősége nem tudom mennyire lehetséges. Maga a chipset nélküliség az olcsóbbá teszi az alaplapokat nem? Ebből a szempontból jó irány lehet, csak ne csesszék el.
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
Szerintem is vállalható kompromisszum kevesebb PCIe, de a vérpisti faktor alacsony lesz, ami nagyon rossz a PR-nak. Bár az is lehet, hogy most az "apró" PC-kre koncentrálnak (lásd RX 480), s a HEDT később jön csak, ahol már lesz chipset a plusz PCIe sávokhoz. Feltéve, hogy megoldható az, hogy a CPU opcionálisan használ chipsetet.
[ Szerkesztve ]
A RIOS rendkívül felhasználóbarát, csak megválogatja a barátait.
-
-
-


![;]](http://cdn.rios.hu/dl/s/v1.gif)

 Tessék figyelni.
Tessék figyelni.  Az Agenánál is 4MB-ot írtak.
Az Agenánál is 4MB-ot írtak.





 De akkor ehhez mérten az eddigi modulon belüli skálázódásnak kakinak kéne lennie, legalábbis a 90%-ból nem tudom hogy lehet 140%-ot csinálni.
De akkor ehhez mérten az eddigi modulon belüli skálázódásnak kakinak kéne lennie, legalábbis a 90%-ból nem tudom hogy lehet 140%-ot csinálni. 


























Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.


- Beszámítás! Intel Core i7 6700K 4 mag 8 szál processzor garanciával hibátlan működéssel
- Beszámítás! Intel Core i9-11900 Processzor - Garancia & Számla - Utolsó Darabok
- Bontatlan 13900KF 3 év magyar kisker garanciával
- Új bontatlan, dobozos, számlás, garanciális i9 13900K CPU akció!
- Intel Core i7-11700K processzor (használt)