- Alsó-középkategóriás, PlayStation 5-be is helyezhető M.2 SSD-t virított a Klevv
- Antec kirakatház Lian Li zöngével és egy csavarral
- Újabb inteles VGA került elő a Biostar hátizsákjából
- Belépőszintű játékos headsetekkel bővült a Corsair kínálata
- Kétféle tájolással munkára fogható, ITX-es ház jött a Sharkoontól
- Milyen billentyűzetet vegyek?
- Melyik tápegységet vegyem?
- Telekom TV SmartBox: szolgáltatói set-top box alacsony korlátokkal
- Fejhallgató erősítő és DAC topik
- Milyen CPU léghűtést vegyek?
- OLED TV topic
- NVIDIA GeForce RTX 4080 /4080S / 4090 (AD103 / 102)
- Kétféle tájolással munkára fogható, ITX-es ház jött a Sharkoontól
- AMD Ryzen 9 / 7 / 5 / 3 3***(X) "Zen 2" (AM4)
- AMD Ryzen 9 / 7 / 5 / 3 5***(X) "Zen 3" (AM4)
Hirdetés
-


Homeworld 3 - Befutott a gépigény és a roadmap
gp A készítők felfedték, hogy milyen hardverek kellenek a játék futtatásához, valamint azt hogy mi vár ránk a későbbiekben.
-


AMD Radeon undervolt/overclock
lo Minden egy hideg, téli estén kezdődött, mikor rájöttem, hogy már kicsit kevés az RTX2060...
-


Van, ahol már törvényben védik az agyhullámainkat
it Az USA-ban még nem volt rá példa, hogy törvényben védenék az agyhullámokat és a mentális adatokon való nyerészkedés miatt aggódnának. Colorado azonban most lépett, mert túl gyorsan fejlődik a neurotechnológia.






-

PROHARDVER!
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-

Bluegene
addikt
3.4 ~0.676x-osa. 4x0.676 = 2.7
rossz. miért 4X0.676? 3X0.676 hisz 12:4=3 tehát 3X annyi mag van, de inkább 2,6 szoros(még ez is optimista) lehet a 12 magos és 4 magos közötti szorzó hisz sohasem skálázódik ideálisan
tehát 2,6X0,676=1,75, tehát szerintem csupán 75%-kal lehet gyorsabb a 965BE-től, az alacsony órajel és a nem ideális skálázódás miatt, így viszont az Intel nyer hiába kevesebb a mag, de a magas órajel és a nehalem architektúra győz
de lehet én számolok rosszul

Siemens S65-re való adatkábelt keresek! egyszeri Szoftverfrissítésre! Írj megbeszéljük ha van elfekvőbe/kölcsön neked!
-

dezz
nagyúr
válasz
 Bluegene
#6552
üzenetére
Bluegene
#6552
üzenetére
Ugh, igaz, tényleg 3x (késő volt).
 Viszont a 2.6-tal nem értek egyet: a renderelés nagyon jól skálázódik (lásd pl. a Gulftown esetét!), a memóriacsatornák száma is megduplázódott. Szóval, én maradok a 3-nál. Bár így is csak ~2x-es szorzó jön ki.
Viszont a 2.6-tal nem értek egyet: a renderelés nagyon jól skálázódik (lásd pl. a Gulftown esetét!), a memóriacsatornák száma is megduplázódott. Szóval, én maradok a 3-nál. Bár így is csak ~2x-es szorzó jön ki.Viszont, ezt alacsonyabb fogyasztással éri el, mint az Gulftown, ami pl. egy renderfarmnál fontos tényező (ha már renderelésről beszélünk, de persze szerveralkalmazásoknál is).
Ami az egyedi munkaállomásokat illeti, nem tudom, mennyi mostanában az Opteronoknál a TDP felső határa, de ha itt is van 125W-os vagy épp 140W-os osztály, jöhetnek még magasabb órajeles 12-magosok.
-
Bluegene
addikt
maradjunk annyiban h körülbelül egyformák renderelésben
az túlzás h a 12magos AMD lealázza
egyébként lesz 8magos nehalem is szerverproci , vhol olvastam
[ Szerkesztve ]
Siemens S65-re való adatkábelt keresek! egyszeri Szoftverfrissítésre! Írj megbeszéljük ha van elfekvőbe/kölcsön neked!
-
-

Oliverda
félisten
válasz
 Oliverda
#6455
üzenetére
Oliverda
#6455
üzenetére
Majdnem eltaláltam...
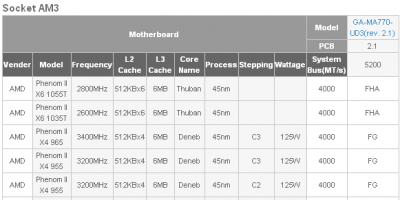

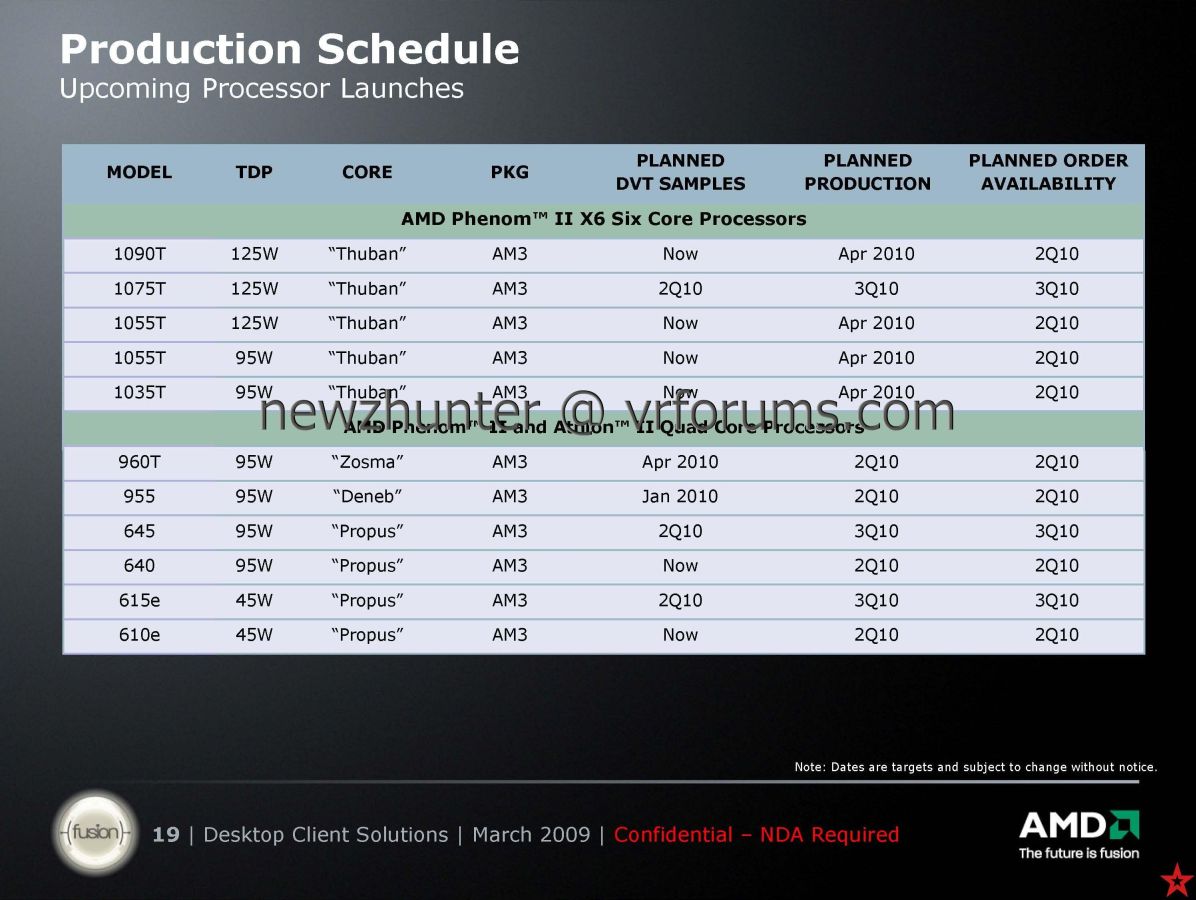
* Phenom II X6 1035T - 2.6GHz - 95W TDP
* Phenom II X6 1055T - 2.8GHz - 95W/125W TDP
* Phenom II X6 1075T - 3.0GHz - 125W TDPAM2 kompatibilitás: pipa
3GHz-es induló órajel: pipa
...viszont 140W helyett 125W TDP-vel.
[ Szerkesztve ]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-

siriq
őstag
Nalam a jatek kezd kihalni. Ok. A bad company-t nyomom most, mast nem. Igazabol szeretnek visszaterni a 3D renderelesi vonalra is(kozben meg hazi servert is epitenek). Szoval nalam a jatek nem igazan szempont(max talan a crysis erdekel).
szerk: hazi server nalam a cisco cuccok meg minden amit ki lehet benne aknazni.
[ Szerkesztve ]
Meg mindig nincs 1000 oras BF3 nev, kozben mar masok is erdeklodnek utana... Mar bevallottan nincs 1000 ora neki... Varjunk Dec 31-ig a Mantle-a.
-
Oliverda
félisten
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
#6562
 DeckardCain
senior tag
DeckardCain
senior tag
DeckardCain
senior tag
-
-

atti_2010
nagyúr
válasz
Bluegene
#6566
üzenetére
Nem hiszem, az AOD-ben ez már nagyon régen benne van, várható volt hogy hardveresen is megcsinálják, amúgy meg nem egy eget verő dolog, inkább azt várom hogy a nem használt magok kikapcsolnak.
1.Asrock FM2A88X+ Killer,A10-5800K,Kingston 2x4Gb 2400Mhz,Int X25-V SSD,SF Pro S.F.-450P14XE. 2.MSI-A75A-G55,A8-3870, Kingston 2x2GB2000, MSI R9-270, Zen 400.
-
Oliverda
félisten
válasz
Bluegene
#6566
üzenetére
Az ötletet szerintem már régen kitalálta valaki de azt, hogy ez konkrétan fűződik-e szabadalomhoz és ha igen akkor az kinek a tulajdonát képezi azt nem tudom.
A technikai megvalósítás eltérő ez szinte biztos.
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
Bluegene
addikt
válasz
Oliverda
#6568
üzenetére
biztos h az Intel féle megvalósítás hatására kényszerült az AMD is fejlesztésre
szal ez az Intel labdája
persze nem vitatom, sok újdonságot épp az AMD valósított meg
valószínű valóban h már nagyon régi szabadalom lehet, elég jó és nyílvánvaló 5let

Siemens S65-re való adatkábelt keresek! egyszeri Szoftverfrissítésre! Írj megbeszéljük ha van elfekvőbe/kölcsön neked!
-
dezz
nagyúr
válasz
Bluegene
#6569
üzenetére
Intel prociban mikor jelent meg először? Csak mert a Barcelona, Agena magonkénti eltérő órajelet is tud, meg nyilván le is állíthatók egyenként a magok (ha nem is fullosan, power gatinggel), csak egy driver kellett volna a dologhoz, sőt az eltérő órajelek által fejlettebb is lehetett volna a sima lekapcsolásnál. Nem hiszem, hogy csak úgy dísznek tették bele, ill. hogy legyen mivel játszadozni egyeseknek az Overdrive programocskában. Azon sem csodálkoznék, ha meg lett volna már a hw alap is az automatikus szabályzáshoz, csak valami nem stimmelt vele, amit csak mostanra sikerült kijavítani (drivert meg lusták voltak írni hozzá, addig is). Bár a külön állítható órajeleket továbbra sem használják ki.
-
Oliverda
félisten
XP alatt működik az eltérő órajeles C'n'Q az összes Phenom-mal csak éppen az windócok elcseszett szálkezelése nem igazán ideális hozzá. Alapértelmezetten ("set affinity" nélkül) win folyamatosan dobálgatja a magok/szálak között a folyamatokat, így a magok nem tudnak lekapcsolni huzamosabb időre, mert amire éppen lejjebb váltanának egy-két p-state-et addigra már kapcsolhatnak is feljebb. Ennek köszönhetően be is lassul az egész hóbelebanc. Vista és 7 alatt már csak párhuzamosan mozognak a magok órajelei ezzel kiküszöbölve a fenti problémát. Amúgy ez a turbo-nak is keresztbe tesz/tehet.
"C'n'Q in Phenoms is slow compared to how Intel Turbo can switch speeds.The biggest problem with dynamic core clocking - delay between states. AMD's new Thuban and Lisbon core supposedly address that problem by moving all power controlling logic into CPU. This should ensure faster p-state switching and less delay. In return we should get less hit from retarded Windows task scheduler when doing light workloads."
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
Oliverda
félisten
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
-
Oliverda
félisten
Kíváncsi vagyok hogy a gyakorlatban ez hogyan fog működni de az nem lenne rossz ha 3 mag menne fel 3.6-ra az 1090T-nél. Mondjuk van egy olyan sejtésem hogy a windows ebbe bele fog köpni.
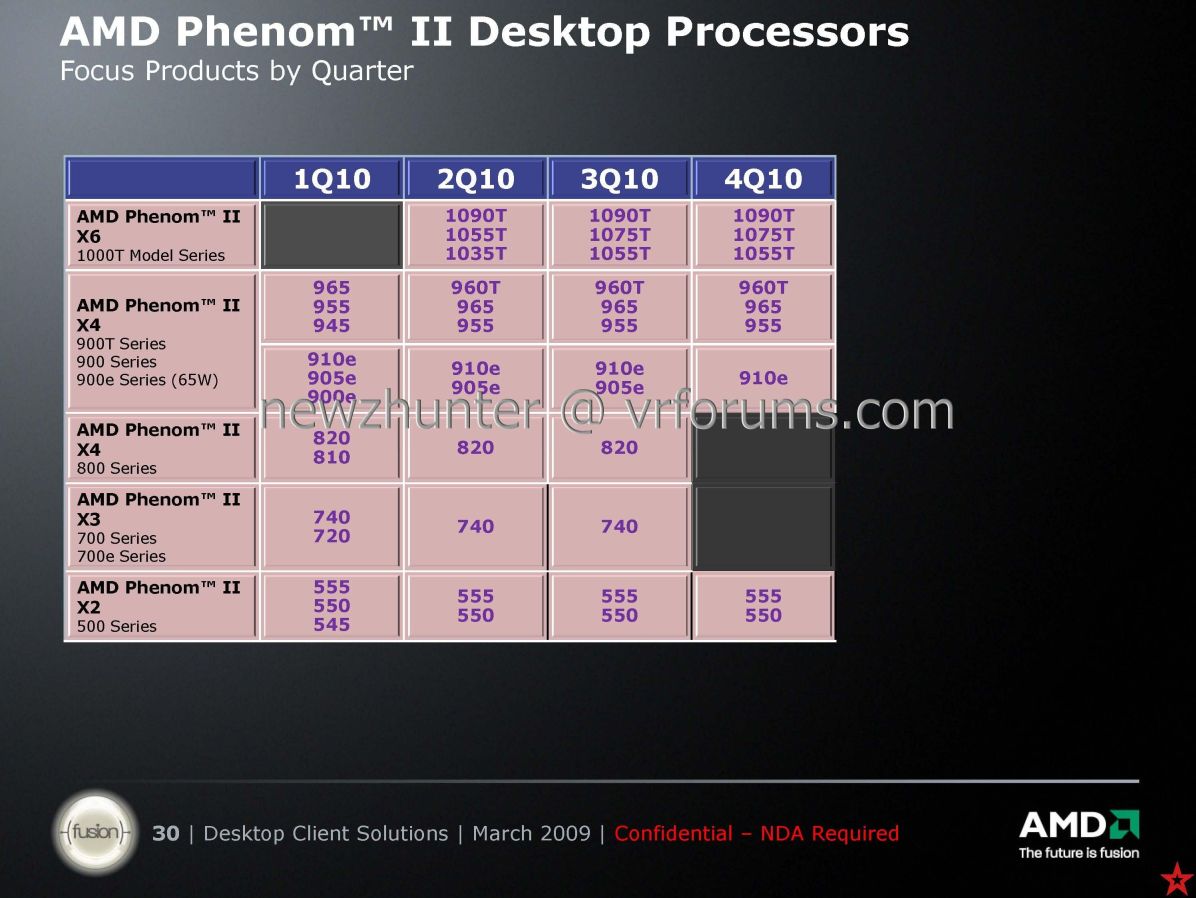
Amúgy elvileg még ebben a hónapban startol a Maranello és a San Marino is.[link]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-

TRitON
aktív tag
válasz
Oliverda
#6576
üzenetére
"Mondjuk van egy olyan sejtésem hogy a windows ebbe bele fog köpni."
Most akkor ez hogy is van? Azt tudom, hogy a WinF*s dobálja a szálakat a processzormagok között, így nem tud normálisan működni a Kúlendkvájet. Ugyanez a hiba Intel cuccoknál is jelen van? Driverrel, vagy egy frissítéssel ezt nem lehet kiküszöbölni?
Mi az? 3 lába van mégsem tranzisztor? - ??? - Traffipax...
-
Oliverda
félisten
Próbáld ki. Indíts el mondjuk egy Super PI-t és látni fogod, hogy egy négymagos procinál ha nem állítasz affinity-t akkor minden magot 25%-on terhelni a win és nem egyet 100%on. Kétmagosnál 50-50%.
Tud normálisan működni mert (már) párhuzamosan mozognak a magok órajelei. Nem tudom hogy az Intel-nél ez hogy működik de gyanítom hogy ott is hasonló módon mivel a windows ezen tulajdonsági minden CPU-ra ugyanúgy vonatkozik. Nem hiszem higy driver-rel kiküszöbölhető. Ez a kernel sajátossága.
akosf
2011-ben de ennek az Intel HyperThreading-jéhez nem sok köze lesz. Az AMD CMT-ben (Cluster-based Multi-threading) gondolkozik és nem SMT-ben. Tekerj kicsit visszább és már találni fogsz róla itt infókat.
[ Szerkesztve ]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-

#95904256
törölt tag
válasz
Oliverda
#6583
üzenetére
Köszönom a tippet! Visszatekertem és elolvastam azt amit a CMT-vel kapcsolatosan találtam, de némiképp homályos maradt a dolog. Olyasmi kép állt össze bennem, hogy a CMT egy programszál egymást követő utasításait lesz képes külön-külön végrehajtó egységeken is futtatni.
Szerintem az SMT bevezetése hatékonyabb lenne, mert már a mostani processzormagok is képesek egy órajel alatt akár 4-5 utasítás végrehajtására. Tapasztalatok alapján a throughput elméleti maximumának további növelése már nem okozna jelentős javulást a valós IPC értékeken. De az is lehet, hogy épp a CMT lényegét nem sikerült megértenem.
[ Szerkesztve ]
-
Oliverda
félisten
válasz
 #95904256
#6584
üzenetére
#95904256
#6584
üzenetére
Egyelőre kb ennyi a hivatalos belőle:


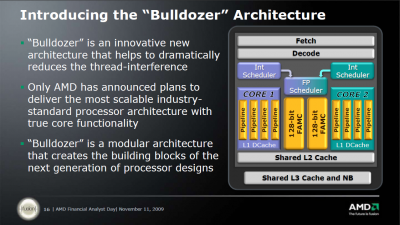
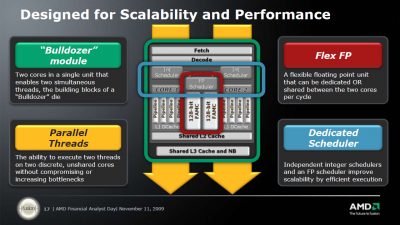
Ami nem hivatalos:
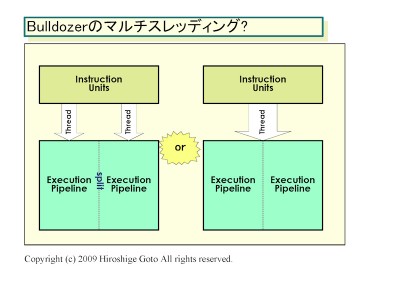


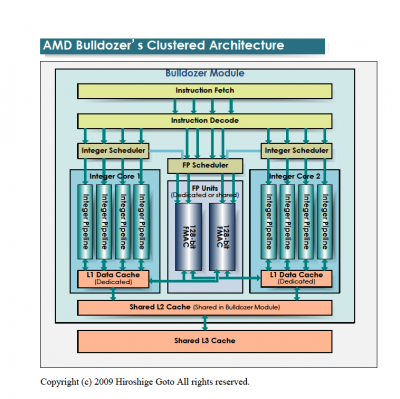
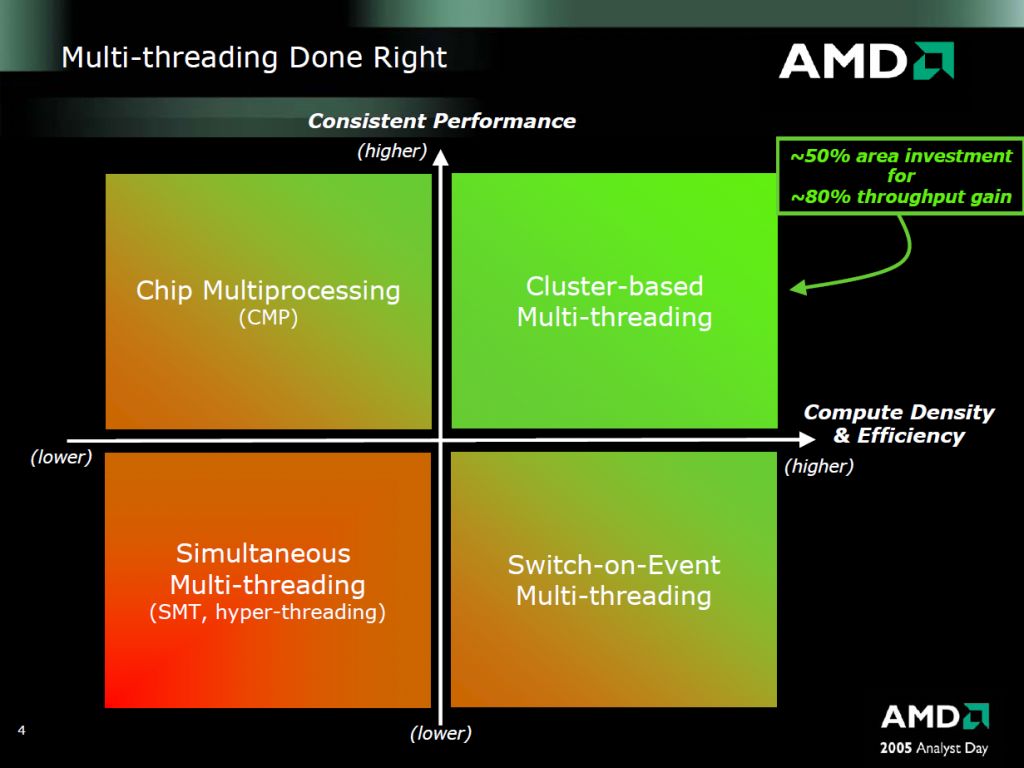
A CMT-ről:
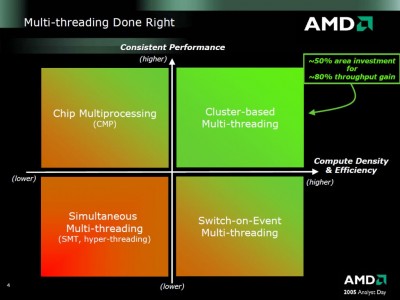

(ez nagyítható)
Tehát itt épp arról van szó hogy a CMT hatékonyabb, azaz jobb terület/teljesítmény mutatója, valamint nincs meg az a hátránya mint a HT-nek, hogy bizonyos alkalmazások nem hogy gyorsulnának de még inkább belassulnak a hatására. [link]
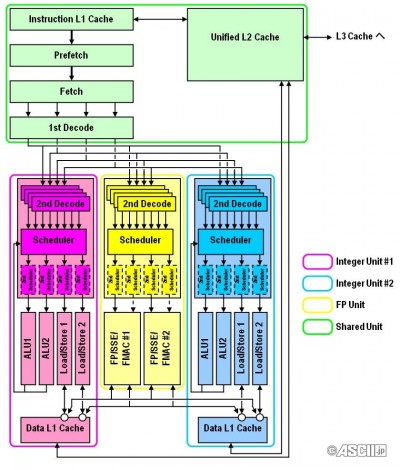
A Bulldozer-nél a "core" részegység mint olyan megszűnik létezni és "module" lesz helyette. Amit feljebb látsz az egy darab modul. Egy ilyet két magnak fog látni az OS. Az L1 I-Cache, az L2 és az FPU megosztott lesz a modulon belül, de terheléstől függően dinamikusan használhatóak lesznek ezen részegységek erőforrásai. Tehát pl. egy egy szálat terhelő alkalmazásnál a teljes FPU sávszélesség használható lesz. A modulok egy nagyobb megosztott L3-mal lesznek összekötve. A legnagyobb egy lapkás verzió elvileg 4 modult fog tartalmazni (32nm-en).
Ez sem hivatalos:
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
#95904256
törölt tag
válasz
Oliverda
#6585
üzenetére
Köszönöm, hogy összeszedted az infókat!
Ez így valóban más megközelítést sugall, mint ahogy elsőre gondoltam. Érdekes és jelentősen eltérő megközelítése az erőforrások kezelésének az SMT-hez képest.
Kíváncsi vagyok, hogy fog teljesíteni. Szerintem várható, hogy mindig az SMT előtt lesz. A plusz tranzisztorok helyigénye pedig nem lesz túl jelentős. Szóval, jónak tűnik.

-
Oliverda
félisten
válasz
#95904256
#6586
üzenetére
Nincsmit.
Amúgy az SMT (állítólag) sosem volt téma:
When Intel announced Hyper Threading, AMD wasn't (publicly) paying any attention at all to TLP as a means to increase overall performance. But now that AMD is much more interested and more public about their TLP direction, we wondered if there was any room for SMT a la Hyper Threading in future AMD processors, potentially working within multi-core designs.
Fred's response to this question was thankfully straightforward; he isn't a fan of Intel's Hyper Threading in the sense that the entire pipeline is shared between multiple threads. In Fred's words, "it's a misuse of resources." However, Weber did mention that there's interest in sharing parts of multiple cores, such as two cores sharing a FPU to improve efficiency and reduce design complexity. But things like sharing simple units just didn't make sense in Weber's world, and given the architecture with which he's working, we tend to agree.
A megvalósításhoz szükséges plusz szilíciumról meg ezt állítják:
"If you were to pull one core from each module, you would remove ~5% of silicon from the total die."
Valamint optimális esetben állítólag 80%-ot is hozhat a megoldás. Még mielőtt valaki megkérdezi hogy ez hogyan jött ki, nem tudom mert nem én számoltam. A HT esetében ugyanez 20%.
[ Szerkesztve ]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
-

fLeSs
nagyúr
válasz
Oliverda
#6587
üzenetére
Egy AMD-s fószertól nem is várhatod, hogy mást mondjon.
Btw akárhogy is tagadják sokan, a HT jól jön az asztali PC-kben, szal az hogy nincs semmi értelme igen messzi áll a valóságtól. Ha 0 értelme lenne, akkor az i7 HT-vel ugyanolyan gyors lenne, mint anélkül, pedig jópár helyen ki lett mérve, hogy ez nem igaz.Frednek
 abban igaza van, hogy két szál osztozkodik a futószalagon, és ez így önmagában tényleg rosszul hangzik. Csak azt elfelejti megemlíteni, hogy a HT nem mindig működik. Csak akkor lép működésbe amikor a fő szál várakozik vmire (mondjuk adat a memóriából), ilyenkor hogy a várakozás alatt is történjen vmi, aktiválódik a virtuális proci. Szal a HT nem azért van, hogy elvegye az erőforrásokat a valódi procimagtól, hanem azért, hogy amíg az várakozik, addig is történjen számolás egy másik szálon.
abban igaza van, hogy két szál osztozkodik a futószalagon, és ez így önmagában tényleg rosszul hangzik. Csak azt elfelejti megemlíteni, hogy a HT nem mindig működik. Csak akkor lép működésbe amikor a fő szál várakozik vmire (mondjuk adat a memóriából), ilyenkor hogy a várakozás alatt is történjen vmi, aktiválódik a virtuális proci. Szal a HT nem azért van, hogy elvegye az erőforrásokat a valódi procimagtól, hanem azért, hogy amíg az várakozik, addig is történjen számolás egy másik szálon.Az AMD azért nem implementálta, mert ahhoz át kellett volna tervezni a K8-at, talán volt bennük egy kis "csakazértsem" hozzáállás is, és még az is lehet, hogy a K8 backend-je nem profitált volna belőle, ezt csak ők tudják, biztos vagyok benne, hogy futottak szimulációk erre vonatkozóan. Az is lehet, hogy az IMC bevezetésével arra gondoltak, hogy a memória közel van (alacsonyabb latency) szal nincs szükség a HT-ra.
[ Szerkesztve ]
"I press keys on a keyboard all day and click a mouse in front of a glowing rectangle. Somehow that turns into food and shelter."
-
#95904256
törölt tag
Szerintem az Intel féle HT-nél nincs fő és alárendelt szál. Ha így lenne, akkor az hamar kiderülne egy egyszerű teszttel. Egyszerűen el kell indítani mndkét szálon egy olyan programot ami alaposan kihasználja az erőforrásokat. Ekkor az alárendelt szál jelentősen lassabban futna, de nem így van. Mindkét szál közel egyforma mértékben lassul vissza, ami attól lehet, hogy az erőforrások kiosztása egyenletes. Azaz a két szál egyenrangú.
[ Szerkesztve ]
-
Oliverda
félisten
Igen, hogy a P4-ről már ne is beszéljünk.
Mondjuk a Bulldozer egy kicsit radikálisabb újításokat fog hozni a K10-hez képest mint a K10 hozott a K8-hoz képest. Nyilván ez önmagában semmire sem garancia. Még kissé homályos az architektúra.
#6592:
Két dolog van. Egyrészt az az interjú majdnem kereken 5 éves, 2005 márciusából való. Gondolom fel tudod idézni hogy akkor mi volt a helyzet. Másrészt az én értelmezésem szerint sehol sem állította Fred hogy nincs semmi értelme.
...he isn't a fan of Intel's Hyper Threading in the sense that the entire pipeline is shared between multiple threads. In Fred's words, "it's a misuse of resources."
Ez szvsz messze nem azt jelenti hogy nincs semmi vagy 0 értelme lenne.
"However, Weber did mention that there's interest in sharing parts of multiple cores, such as two cores sharing a FPU to improve efficiency and reduce design complexity. But things like sharing simple units just didn't make sense in Weber's world, and given the architecture with which he's working, we tend to agree."
Ezt pedig már nem Fred barátunk mondta hanem a drágalátos jómadár Anand Lal Shimpi rittyentette oda.
Már 2005-ben is arról beszéltek, hogy majd inkább a CMT-t fogják alkalmazni a jövőben ha odakerülnek. Ez egy 2005-ös slide. A CMT (elvileg) hatékonyabb mint az SMT, valamint nincsenek olyan mellékhatásai, hogy bizonyos alkalmazásoknál még inkább hendikepet jelent a bekapcsolása nem pedig előnyt. Nyilván nem az ilyen alkalmazások vannak többségben de azért pár helyen kifejezetten javasolják a HT kikapcsolását:
* A consultant who deals with Cognos, a leading BI software by IBM, recommend disabling HyperThreading because it “frequently degrades performance and proves unstable.”
* Microsoft recommends turning off HyperThreading when running PeopleSoft applications because “our lab testing has shown little or no improvement.”
* A Microsoft TechNet article recommends disabling Hyper-threading for production Exchange servers and “only enabled if absolutely necessary as a temporary measure to increase CPU capacity until additional hardware can be obtained.”
* Advanced Clustering found when running High Performance Linpack (HPL) that “Using HT on the other hand causes a ~10% drop in performance compared to HT not being used.”
Itt az iXBT-s tesztben lévő felső két táblázat eredményei sem éppen rózsásak ebben ez ügyben.

Hogy miért nem implementálták azt sosem fogjuk biztosan megtudni de én erősen kétlem, hogy megengedhették volna maguknak a "csakazértsem" hozzáállást. Pár fórumon lelkes tagok azzal foglalatoskodnak hogy az AMD elmúlt bő 1 évtizedben bejegyzett patentjeit túrják, és ha jól emlékszek találtak olyan patentet amit még valamikor 2000 körül jegyeztek be és már a CMT-vel állt kapcsolatban. Ergo én azt sem tartom kizártnak, hogy az évek során előre megfontoltan úgy alakították ki a fejlesztési stratégiájukat, hogy abba semmilyen módon nem fért volna bele az SMT.
[ Szerkesztve ]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-

P.H.
senior tag
Amikor az OS két szálat ütemez a magra, azokat párhuzamosan próbálja futtatni az Intel összes HT implementációja.
Netburst HT: "Both logical processors compete for the Trace cache access each clock. If their requests come in simultaneously, the Trace cache access is granted in turns to each of them every other clock. In other words, the first one accesses the Trace cache on the first clock, the second – on the second, then the first one access Trace cache again on the third clock, etc. If one of the threads is stalled (of there are no decoded micro-operations in the Trace cache for this thread), then the second thread has the Trace cache at its full disposal." ([link])
Core I7 HT: "The instruction fetcher and decoders are shared evenly between the two threads so that each thread gets every second clock cycle." [...] "There is no way to give one thread higher priority than the other in the CPU." ([link])
Az Atomban két decoder van: "The two instruction decoders are identical." [...] "It is impossible to assign different priorities to two threads running in the same core. Thus, a low priority thread may take resources from a high priority thread running in the same core, with the unfortunate result that the high priority thread runs at only half the maximum possible speed." ([link])
[ Szerkesztve ]
Arguing on the Internet is like running in the Special Olympics. Even if you win, you are still ... ˙˙˙ Real Eyes Realize Real Lies ˙˙˙
-
Oliverda
félisten
válasz
Oliverda
#6594
üzenetére
Ha már szóba került az SMT pontosabban a HT akkor itt egy teszt amibe na Netburst és a Nehalem HT hatékonyságát próbálják összemérni:
Pentium XE vs Core i3 Hyper-Threading review
Itt meg egy kis találgatás:
Llano core: potentially superior to Nehalem - clearly!... yes i believe so!.. 32B fetches with (if the announcement about improved fetch materializes) similar branch/loop handling as Nehalem, much better execution with cluster design and 6 ports for execution units with an augmented (84 to 72 entries meaning an augment of ~15% in the instruction window(ROB) along with many tweaks allover, how difficult would be to push that to +20% performance over Deneb ?) instruction window on par with Nehalem, improved(much?) memory fill with forwarding schemes and disambiguation close or on par with nehalem.. yet clearly bottlenecked at decode with only 3 decode slots( it doesn't but only if it could borrow the o-o-o decode slots of BD ! )... but its "balanced" and clustered nature should make it much more clock friendly than Nehalem... I wouldn't be surprised if the gain is close to 20% comparing core to core at the same clock with K10... also considering "turbo" and power management... It should mark the end of the narrower(3 wide) and faster single thread core processors... yet i hope we will see an improved Llano2...
Bulldozer: truly advanced. Yet IMHO, bottlenecked at decode with only 4 decode slots( yet advanced o-o-o design) for the potential of 2 threads. "IF" with only 2 ALU per core/cluster if should also be bottlenecked at execution, considering that the 2 core clusters are independent and never work together.
This processor with 2 L1-$I cache blocks interleaving accesses consecutively, it seems that is the rumor now, should be a fetch monster, and if it provides "value prediction" with superb re-execution mechanisms upon a much better memory fill and all the other techs to speed up the back end, it should really be a "throughput" monster... yet that decode bottleneck and narrow execution upon each thread should help nothing. BD screams for Macro-ops and uOPs fusion as it is( has identical problems of core2 and Nehalem) .
Clock to clock it should be in league with Llano core at single thread execution ( perhaps a "startegic" decision... for not trashing Llano sales ?)... perhaps a tiny little better, yet clearly inferior to SB at single thread execution with 3 ALUs and 6 ports for 2 threads ( "IF" there is only 2 ALUs per core/clusters in BD). But OTOH it "could" be a speed monster, compensating that way its inferior fixed point(INT) narrowness. If only 1 more decode slots at the front end, and 1 more ALU at each core/cluster, and this processor would completely burier SB, if not at single thread then at multithreading when the 2 cores are actives; that is, firing 2 threads in the same module would not hurt fixed point(INT) execution in any of the core/clusters, as it seems it might happen now...
Ugyanez a Sandy Bridge-ről:
An evolution of Nehalem, a more elaborated tick not a tock. Yet it addresses one of the more fundamental bottlenecks of Nehalem at execution with 6 ports for the execution units. The rest should be more tweaked accounting for Hyperthreading. "IF" the front-end has separated L1-$i cache blocks for the 2 simultaneous threads it should also improve this fetch 16B bottleneck upon single thread code, it remains to be seen if it can achieve 20% over Nehalem which i doubt... nevertheless it should provide a good boost over Nehalem. ZeroingIdioms should give the entrance into FMAC execution with compiler oriented "code transformations" and in here there is a serious advantage, if for nothing else, at benchmarketing with Intel code.
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
Oliverda
félisten
-

Thrawn
félisten
Different songs for different moods. łłł DIII Thrawn#2856 łłł Look! More hidden footprints! łłł D4BAD łłł WoT: s_thrawn łłł





 Viszont a 2.6-tal nem értek egyet: a renderelés nagyon jól skálázódik (lásd pl. a Gulftown esetét!), a memóriacsatornák száma is megduplázódott. Szóval, én maradok a 3-nál. Bár így is csak ~2x-es szorzó jön ki.
Viszont a 2.6-tal nem értek egyet: a renderelés nagyon jól skálázódik (lásd pl. a Gulftown esetét!), a memóriacsatornák száma is megduplázódott. Szóval, én maradok a 3-nál. Bár így is csak ~2x-es szorzó jön ki.

























![[/IMG (IMG:http://blogs.amd.com/work/wp-content/uploads/2010/03/image0021.jpg)(/IMG)]](http://blogs.amd.com/work/wp-content/uploads/2010/03/image0011.jpg "[/IMG (IMG:http://blogs.amd.com/work/wp-content/uploads/2010/03/image0021.jpg)(/IMG)]")









Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

