Az idei GDC-n a Frostbite Team egy igen érdekes előadás formájában jelezte, hogy úrrá lettek egy jelentősnek mondható problémán. Graham Wihlidal, a vállalat programozója ugyanis kidolgozott egy olyan leképezőoptimalizálást, amely a grafikus futószalagot némi compute-tal fűszerezi, leginkább azért, hogy jobb legyen a háromszögek kirajzolásának hatékonysága.
Az alapötletet a Playstation 3 libEdge adta, amely igen hatékonyan szabadította a játékokat a nem látható, vagy végeredmény szempontjából nem fontos háromszögektől. Az új alap egy compute-alapú, azaz GPGPU-s háromszög kivágási rendszer lett, amely már a prototípus fázisban jó eredményeket adott. Kiderült, hogy a Microsoft is dolgozik a Frostbite Team által elemzett problémán, így sok adatot meg tudtak osztani egymással, majd nem sokkal később az AMD is beköszönt, ugyanis elárulták a partnereknek, hogy készül egy GeometryFX nevű konstrukciót, amely szintén a háromszögek hatékonyabb kezelését szorgalmazza. A Frostbite Team saját rendszere tehát egy igen kevert csomag, mivel a fejlesztésénél a Microsoft információit, és az AMD szoftvertechnológiáját is felhasználták, és ezekből született meg egy igen kellemes végeredmény.
Az alapproblémát egyébként a DirectX 12-höz hasonló explicit API-k jelentik, amelyek azzal az ígérettel jöttek, hogy radikálisan növelhető a kiadott rajzolási parancsok száma. Egy rajzolási parancs azonban sokféle lehet, így a kis és kevés háromszöget kirajzoló parancsok hatékonysága a GPU-ra vonatkozóan nem túl előnyös. Itt a probléma az, hogy a grafikus vezérlőnek a mai kivágási rendszerek mellett gyakorlatilag túl sok üres ciklussal feltöltött, azaz gyakorlatilag látható eredményt nem is adó operációt kell futtatnia, ami lerontja a hatékonyságot. Emiatt a sok rajzolási parancs nem mindig előny.
A cél a kivágási rendszerek újraértelmezése. Ma igen sok munka hárul ebből a szempontból a processzorra, de ez nem kedvező, mivel előnytelen az optimalizálás szempontjából. Egy alternatív iránynak tűnik a compute shader, ezen belül is a kivágási rendszerek jelentős részének GPU-ra történő átrakása. Ennek számos előnye van, többek között számos olyan optimalizálási lehetőség adódik, amelyek eddig nem voltak célszerűek, továbbá a rajzolásokat innentől kezdve nyers adatként lehet kezelni, ami azért előny, mert az adat előre felépíthető, gyorsítótárazható, illetve újrahasználható, így számos olyan fixfunkciós egységekből eredő limitáció megkerülhető, ami korábban gondot jelentett.
Ahhoz, hogy a kivágás a GPU-kon működjön úgynevezett GPU által vezérelt futószalagot kell tervezni. Ilyenkor olyan kötegelés lesz alkalmazva, ahol az egyes egymáshoz fűzött felületeknek ugyanazt a shadert kell használni, illetve ugyanazt a vertex és indexszelési lépcsőkön futnak át. Ez viszont ma még gond, mert az ehhez szükséges alapot szabványosan a DirectX 12 kínálta fel elsőként, ugyanakkor az AMD és az NVIDIA a DirectX 11-hez kínál hasonló kiterjesztést.
A kivágás a GPU-n több lépcsőben történik. Elsőként a háromszögklaszterek kivágása a cél, majd el kell távolítani a zéró rajzolásokat, és jöhet a nem látható háromszögek kivágása. Ehhez számos szűrő lehet szükséges, de nem mindegyiket célszerű használni, vagyis ez leginkább az adott leképező sajátosságaitól függ. A megfelelő szűrők kiválasztása és aktiválása után a kötegelés lesz a probléma, ugyanis az biztos, hogy egy bizonyos mennyiségű háromszög túléli a teljes kivágási fázist. Ideális esetben ezek csak látható háromszögek, de lesznek olyanok is, amelyek átmentek a szűrőn, viszont mégsem látszanak. Ezekre természetesen el kell végezni a számítást. A lényeg az, hogy a kivágást túlélő háromszögeket ideiglenes pufferekben kell tárolni. Ez a tervezési része, ugyanis összesen akkora puffer kell, hogy abba biztosan beférjen az összes rostán átszűrődő háromszög. Ez minden esetben egyedi kialakítást igényel, hiszen jelenetkomplexitás eltérő, így célszerű gondosan megtervezni a működést. A megjelenítés szempontjából egyébként az sem lehet baj, ha a túl kicsi az adott részpuffer, mert ettől az adott felülethez tartozó háromszögek leképezésre kerülnek, csak meg kell bontani a munkamenetet és egy extra fázist kell beiktatni, ami nyilván nem a legjobb opció.
Ezzel a modellel a háromszögek feltöltése és a leképezés párhuzamosan működhet, de az első feltöltés például mindenképpen rossz hatékonyságú lesz, mivel nincs még minek futnia párhuzamosan. Ugyanakkor a Frostbite Team erre is megoldást talált, mivel aszinkron compute mellett oda bármi befűzhető.
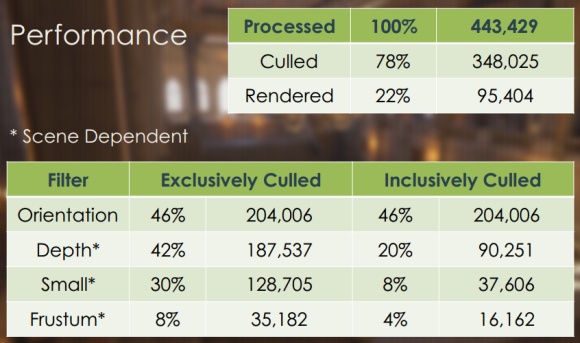
Az eredmények szempontjából a rendszer igen erősnek mondható. A Dragon Age: Inquisitionből származó tesztjelenet Full HD-ben, 443 429 háromszöggel és 171 darab egyedi PSO-val a fenti képen látható eredményt hozta. Látható, hogy annyira hatékony a módszer, hogy csupán a jelenet összes háromszögének a 22%-át kellett leképezni.
A Frostbite Team a tényleges teljesítményt is lemérte a Microsoft Xbox One, a Sony PlayStation 4, illetve az AMD Radeon R9 Fury X termékekre levetítve soros, szinkron és aszinkron módban is. Mindezt tesszelláció nélkül, illetve teszellálással.
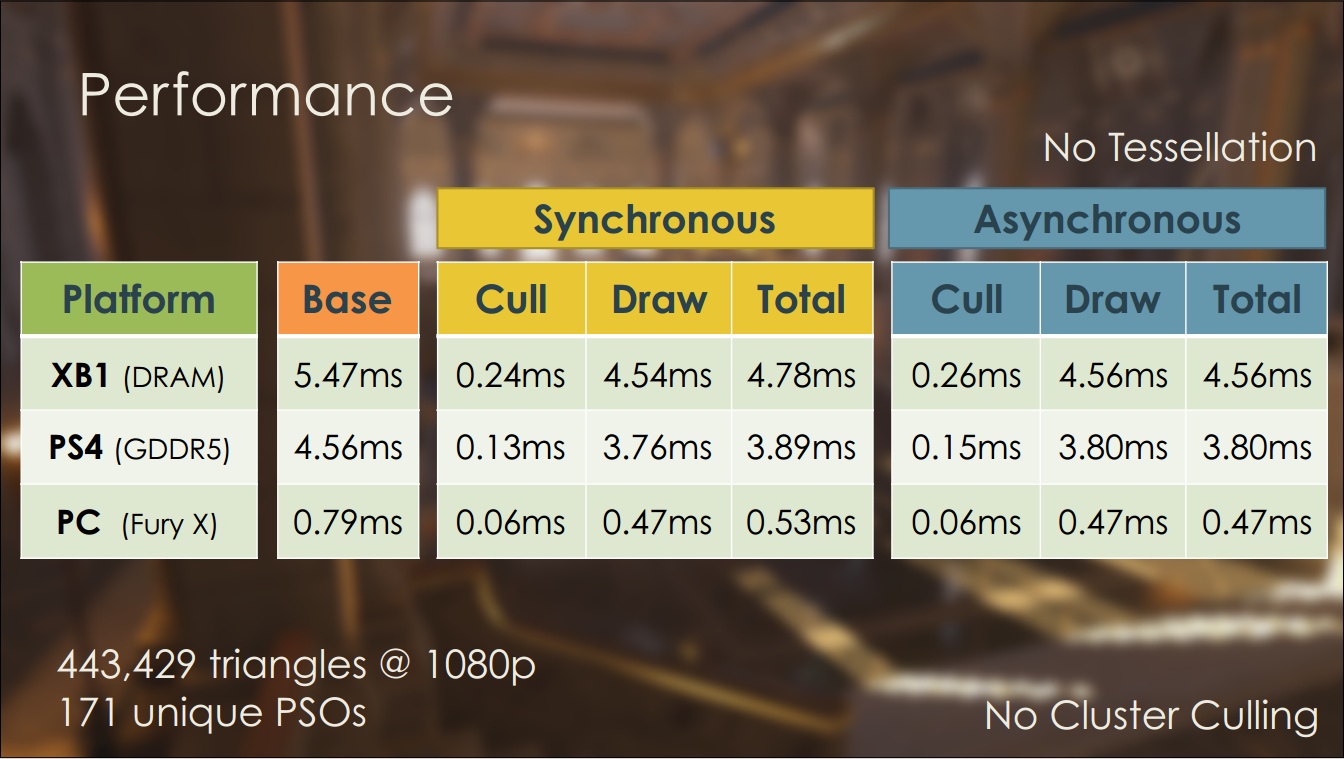

[+]
A rendszer már be van építve a Frostbite legújabb verziójába.



