Komoly tudást kínál a Tonga cGPU
Az AMD a GCN architektúrára egy alapként tekint, de valójában több fejlesztésről van szó, így csak a GCN S.I. (Southern Islands) tekinthető alapnak, míg a modernebb Radeonokban már a GCN C.I. (Sea Islands) verzió található. Ezek különbségeit az alábbi oldalon már leírtuk, de most megérkezett az újabb fejlesztés, amely a GCN V.I. névre hallgat. A Volcanic Islands sorozatba tartozó Tonga cGPU már ide sorolható. Többek között ez az első olyan PC-s grafikus vezérlő, amely technikai szempontból többet tud az Xbox One és a PlayStation 4 konzolok APU-jainak IGP-jénél.
A GCN V.I. egyik legfontosabb fejlesztése a GPU grafika preempció támogatása, amiről az alábbi hírben bővebben beszámoltunk. Ennek az újításnak egy program futtatásakor nincs drámai előnye (hacsak az alkalmazás direkten nem épít rá), viszont a felhasználók általános szokása, hogy a főleg grafikai munkát végző játék mellett a háttérben más programokat is futtatnak. Ezek ma a processzort terhelik, ami persze elvesz némi erőforrást az adott játéktól, de a teljesítményvesztés ismeretében be lehet vállalni a párhuzamos programfuttatást.
A GPGPU során már nem ilyen egyszerű a helyzet, mivel még a kis terhelés is lényegesen rontja az adott grafikus vezérlő játékban felmutatott teljesítményét. Ezzel lényegében lehetetlen elérni, hogy egy háttérben futtatott GPGPU-s alkalmazás ne rontsa le élvezhetetlen szintre a játék sebességét. A GPU grafika preempció bevezetésével azonban ez a probléma megszűnik, mivel a hardver prioritásként tekint a grafikai munkára, így a GPGPU-s alkalmazás feladatait akár számítás közben is megszakítja, ha arra a jó teljesítmény biztosítása érdekében szükség van.
Az új lapkára rátérve elmondható, hogy a Tonga a TSMC 28 nm-es gyártástechnológiájával készül, kiterjedése pedig 359 mm², és ebbe a méretbe 5 milliárd tranzisztort sikerült bepasszírozni. Ez az adat annak tükrében furcsa lehet, hogy a szintén 28 nm-es gyártástechnológiával készülő Tahiti cGPU-ban a 4,3 milliárd tranzisztor 365 mm²-es területet foglal el, azonban a Tonga cGPU-t már a legújabb HDL rendszerrel tervezte az AMD, aminek hála sokkal sűrűbben helyezhetők el rajta a tranzisztorok.
[+]
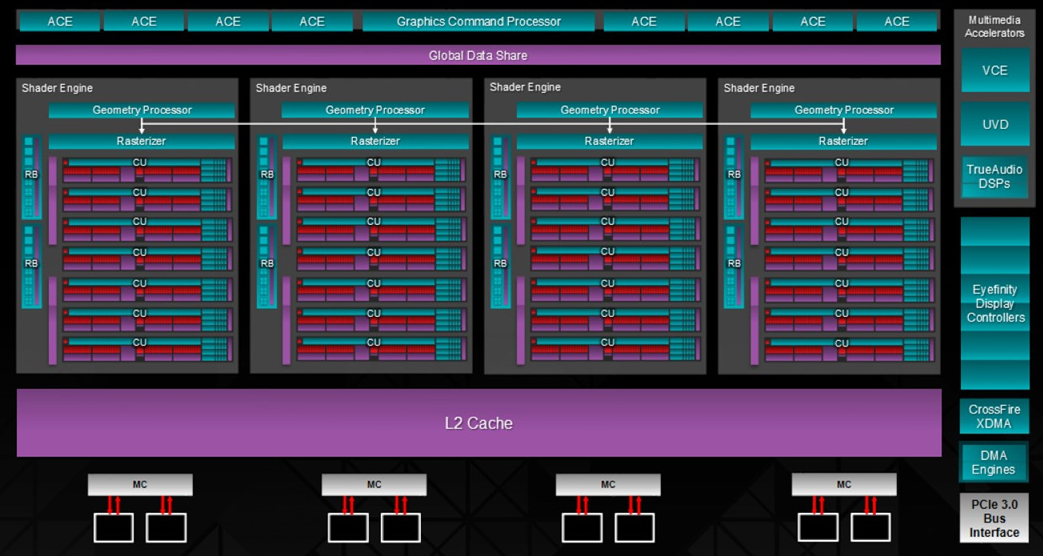
A rendszer alapját természetesen továbbra is a CU, azaz a Compute Unit képzi, ami viszont az eddigi legmodernebb Hawaii cGPU-hoz képest némileg változott. Radikális módosításról persze nincs szó, hiszen megmaradt az egy skalár feldolgozó, illetve négy darab, egymástól teljesen független, 16 utas, azaz 512 bites, multiprecíziós SIMD motor. Egy CU-n belül továbbra is 64 kB-os helyi adatmegosztás, vagy más néven Local Data Share (LDS) található, melyen a négy darab, egyenként 64 kB-os regiszterterülettel rendelkező SIMD motor osztozik. Az LDS mellett egy 16 kB-os adat gyorsítótár is elérhető, melyet a CU írhat és olvashat is.
Az előző bekezdésben már említett skalárfeldolgozó némileg különc a CU-n belül. Ez lényegében egy integer ALU, mely a GCN C.I. hardverekhez képest megduplázott, azaz 8 kB-os dedikált regiszterterületet kapott. A textúrázást CU-nként továbbra is egy blokk oldja meg, mely négy darab, csak szűrt mintákkal visszatérő, Gather4-kompatibilis textúrázó csatornát rejt.
A fentiek mellett a GCN V.I. érdekes funkcionális újításának tekinthető az új 16 bites lebegőpontos és integer utasítások bevezetése. Ennek a PC-ben nem lesz lényeges jelentősége, de az ultramobil piacra tervezett rendszerchipek esetében komoly tényező, hogy az adott feladat alacsonyabb fogyasztás mellett is elvégezhető. A 16 bites utasítások használata a pontosságra nincs kedvező hatással, de a fogyasztásra már igen, így nagyon jellemző, hogy az ultramobil hardvereknél ezt a módot lehetővé teszik a hardverek, hogy az akkumulátor üzemidejével spóroljanak. A GCN V.I. esetében ez a képesség nagyon hasznos lesz a rá épülő rendszerchipekben. Mindemellett a rendszer kapott még adatpárhuzamosságot és feladatütemezést segítő extra utasításokat is.
A GCN C.I. architektúra örökségének részeként a Tonga cGPU is képes a CU-kon belüli LDS-t a geometry shaderek adatainak lementésére használni, ami nagyrészt annak köszönhető, hogy az AMD az LDS-t virtualizálja, tehát a különböző feladatok egymás adatait nem bánthatják. Az ACE egységek sem változtak, így továbbra is nyolc parancslistát kezelnek, illetve saját maguknak is tudnak új munkát adni anélkül, hogy a processzor beavatkozására lenne szükség. Természetesen az ACE egységek az új fejlesztés esetében is képesek szinkronizálni és kommunikálni a GDS-en (globális adatmegosztás) és az L2 gyorsítótáron keresztül.
A cikk még nem ért véget, kérlek, lapozz!



