A jelenleg is zajló Hot Chips 22 rendezvényt használta fel az AMD a Bobcat és a Bulldozer néven ismert, x86-os processzorarchitektúrák részletes bemutatására. A vállalat már az elmúlt év végén felvázolta hosszabb távú terveit, de akkor csak felületesen lehetett információkat kapni az említett rendszerekről.
![[+]](http://cdn.rios.hu/dl/cnt/2010-08/63893/amdbobcatbulldozer.jpg "[+]")
[+]
A Bobcat és a Bulldozer kódnév két irányt jelöl a piacon, mivel ezek a fejlesztések különböző szegmensek igényeit tartották szem előtt, így az eredmény is eltérő lett. A Bobcat egy rendkívül flexibilis rendszer, és az alacsony fogyasztás, illetve a kis helyigény mellett elérhető maximális teljesítmény kipréselése volt a cél. Éppen ezért ez a processzormag a netbookok, nettopok és a felhős számításokhoz optimalizált, alacsony fogyasztás kliensek területére ajánlható. A Bulldozer gyakorlatilag ennek az ellentéte. A fogyasztás másodlagos szempont volt a teljesítmény és a skálázhatóság mögött, így ez a fejlesztés a nagyteljesítményű asztali vagy mobil PC-k, valamint a szerverek piacán szeretne hódítani.
Többszálú munkavégzés hatékonyan
A Bulldozer alapvetően új koncepcióra épít az x86-os processzorok történelmében. Az új rendszer esetén először feltehető az a kérdés, hogy mit nevezünk processzormagnak. A szerverek esetén ez kifejezetten fontos szempont, ugyanis a szoftverek licenszei jelenleg a rendszerben fellelhető magok számához vannak kialakítva, ám ez a modell az új processzorok megjelenésével számos kérdőjel elé állítja a cégeket. Az AMD a fejlesztése kapcsán úgynevezett Bulldozer modulokról beszél, amelyben két integer maghoz kapcsolódik egy megosztott lebegőpontos feldolgozó. Az, hogy a modul önmagában processzormagnak tekinthető-e, nagyban függ az adott szoftver fejlesztőitől, akiknek el kell dönteniük ezt a kérdést. Erre megvannak a különböző logikára épülő technikák, ám ezek más eredményeket adhatnak az újfajta felépítést alkalmazó modul esetében. Éppen ezért ez a licenszelési séma leáldozóban van, hiszen a későbbiekben – például az esetleges vektorprocesszorok bevetésekor – további kérdések merülhetnek fel.
![[+]](http://cdn.rios.hu/dl/cnt/2010-08/63893/bulldozersres.jpg "[+]")
A Bulldozer modul [+]
A Bulldozer alappillére a többszálú feldolgozás CMT-szerű (Cluster-based Multi-threading) megvalósítása. Mint ismeretes, egy processzormagon belül számos megoldás van több feldolgozási szál kezelésére. A legelterjedtebb elgondolás az SMT (Simultaneous Multi-threading), amit például az Intel is alkalmaz a Hyper-Threading technológia égisze alatt. Az SMT nagyon kis tranzisztorigénnyel rendelkezik, miközben egy megfelelően optimalizált kód végrehajtásának idejét akár 20-25%-kal is csökkentheti. Ezzel ellentétben persze problémák is felüthetik a fejüket, mivel a program optimalizációja kulcsfontosságú. Volt már rá példa, hogy a processzor teljesítményét az aktív Hyper-Threading fogta vissza, ami azzal magyarázható, hogy a processzormagon belül a két szál közös hardvert használ, azaz szó szerint küzdenek egymás ellen az erőforrás birtoklásáért. A CMT esetében ez nem fordulhat elő, mivel a feldolgozási szálak dedikált végrehajtóegységeket kaptak. Az elérhető gyorsulás az optimalizálástól függ, de átlagosan 80%-os teljesítménynövekedésre van kilátás. Természetesen a dedikált erőforrások nagyobb tranzisztorigényt jelentenek. Az AMD elmondása szerint az extra integer mag 12%-kal növeli meg a Bulldozer modul méretét, ami nem nevezhető nagy befektetésnek, különösen akkor, ha figyelembe vesszük az elérhető gyorsulást.
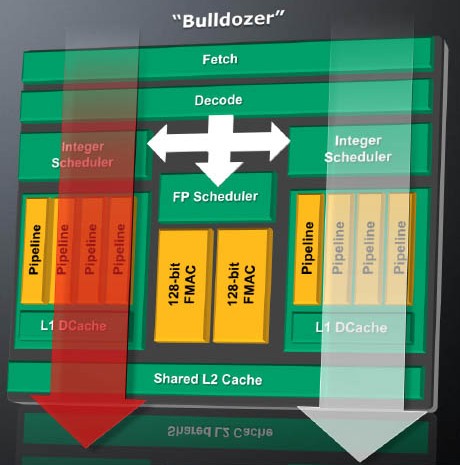
CMT-szerű többszálúság
A Bulldozer modulban fellelhető két darab úgynevezett integer cluster dedikált gyorsítótárat használ az adatok tárolására. Az egy-egy feldolgozási szál ezekhez az egységekhez tartozik, ám nem szabad megfeledkezni a két darab lebegőpontos, 128 bites FMAC feldolgozóról sem, ami logikai szinten a két integer cluster között helyezkedik el, és alapértelmezés szerint egy-egy ilyen SIMD motor tartozik a szálakhoz. A rendszer azonban képes felismerni a várható terhelést, így igény esetén mindkét lebegőpontos feldolgozót hozzárendelheti az egyik clusterhez, így növelve a működés hatékonyságát. Itt nagy szerepe lehet az Intel AVX utasításkészlet bináris támogatásának, hiszen a motorok összefűzése 256 bit széles feldolgozót eredményez. Újdonság lesz még az Intel SSE4.1 és SSE4.2, valamint az AES, illetve az AMD SSE5-ös vonalról megismert FMA4, XOP és CVT16 támogatása. Az FMA4 kiterjesztés komoly fegyvertény lehet, hiszen a fejlesztők évek óta szeretnék a sokszor használt MAD (a*b+c) utasítást összefűzni, ami a jelenleg alkalmazott, két részre bontott számításnál pontosabb eredményt ad.
![[+]](http://cdn.rios.hu/dl/cnt/2010-08/63893/bulldozerdesign.jpg "[+]")
[+]
A Bulldozer architektúrára épülő processzorok 2011 második felében láthatnak napvilágot, és a GlobalFoundries 32 nm-es SHP gyártástechnológiáján készülnek. Először a szerverek piaca lesz bevéve, majd ezt – várhatóan ősszel – követi az asztali verzió. Utóbbi szegmensbe a Socket AM3+ tokozással érkeznek a termékek, ám arról továbbra sincs hivatalos információ, hogy a processzorok működnek-e a Socket AM3-as alaplapokban.
APU-ban a jövő
Az AMD a szerverek és a nagyteljesítményű számítógépek mellett az átlagos igényekre is gondol, ahol az APU-k fognak hódítani. A Bobcat a nagyon alacsony fogyasztású termékek esetében kerül bevetésre. A rendszer a Bulldozertől eltérő irányelveket követ, hiszen kritikus szempont volt az energiagazdálkodás, és az architektúrára alapozó Ontario lapka kiterjedése. Függetlenül attól, hogy a processzormag kis méretét tartotta szem előtt az AMD, az utasítások sorrendtől független végrehajtása biztosított, azaz a rendszer out of order elvű feldolgozást alkalmaz, továbbá a magok két x86-os dekódolót tartalmaznak. A Bobcat számos energiagazdálkodási funkciót használ, ami segít a fogyasztást megfelelő szinten tartani. Az x86-os architektúra egyébként támogatja az AMD 64 bites kiterjesztését, az SSE1, SSE2, SSE3 és SSSE3 utasításkészleteket, valamint az úgynevezett biztonságos virtualizációt.
![[+]](http://cdn.rios.hu/dl/cnt/2010-08/63893/bobcatcore.jpg "[+]")
[+]
Az Ontario lapkáról már számos adatot lehetett tudni, így a TSMC 40 nm-es LP gyártósorain készülő chip két Bobcat processzormagot és egy integrált grafikus vezérlőt tartalmaz. Utóbbi meglehetősen nagy tudás birtokában lesz, mivel a jelenleg hódító Evergreen generáció továbbfejlesztésének tekinthető. A grafikus mag támogatni fogja a DirectX 11-es API-t, a DirectCompute 5.0-s és az OpenCL 1.1-es felületet, valamint az UVD modul képes a Full HD-s videók és a flashanimációk gyorsítására, sőt valószínűnek tűnik a VP8-as kodek támogatása is, ami a WebM és a HTML5 tartalmak gyorsabb feldolgozását teszi lehetővé.
![[+]](http://cdn.rios.hu/dl/cnt/2010-08/63893/bobcat.jpg "[+]")
[+]
A Bobcat és a Bulldozer architektúrára épülő chipek között az űrt a Llano tölti majd be, ami a GlobalFoundries 32 nm-es SHP gyártástechnológiáját használja. Ez az APU az Ontarióhoz hasonló technológiai tudást tudhat magáénak, ám a teljesítménye nagyobb lesz.
Fontos megjegyezni, hogy az AMD ugyan nem beszélt részletesen az órajelekkel való játékról, ám mindegyik érkező lapkában lesz valamilyen turbó technológia, ami a nem használt erőforrások órajelét lecsökkentve megemeli az aktívan dolgozó egységek teljesítményét. A konkrét működésről még nem lehet tudni, de a Bulldozer esetében a modulokon belül történik a nem használt feldolgozási szál lekapcsolása, míg az APU-k a grafikus mag erejét is képesek növelni a processzormagok órajelének csökkenése esetén.
VISION kiterjesztve
Az AMD a marketingnél minden szempontból a platformra fog építeni, amit a VISION matricák fognak részletezni. Ezt az elgondolást a jövőre megjelenő Catalyst meghajtó tovább erősíti a platformszintű támogatással, így egy teljesen AMD-s rendszer számos előnyt kínálhat többek között az energiagazdálkodás szempontjából.








